On each of the last two Fridays, Google has suspended SSLMate's Google Cloud access without notification, having previously suspended it in 2024 without notification. But this isn't just another cautionary tale about using Google Cloud Platform; it's also a story about usable security and how Google's capriciousness is forcing me to choose between weakening security or reducing usability.
Apart from testing and experimentation, the only reason SSLMate still has a Google Cloud presence is to enable integrations with our customers' Google Cloud accounts so that we can publish certificate validation DNS records and discover domain names to monitor on their behalf. We create a service account for each customer under our Google Cloud project, and ask the customer to authorize this service account to access Cloud DNS and Cloud Domains. When SSLMate needs to access a customer's Google Cloud account, it impersonates the corresponding service account. I developed this system based on a suggestion in Google's own documentation (under "How can I access data from my users' Google Cloud project using Cloud APIs?") and it works really well. It is both very easy for the customer to configure, and secure: there are no long-lived credentials or confused deputy vulnerabilities.
Easy and secure: I love it when that's possible!
The only problem is that Google keeps suspending our Google Cloud access.
The First Suspension
Google suspended us for the first time in 2024. Our customer integrations began failing, and logging into the Google Cloud console returned this error:
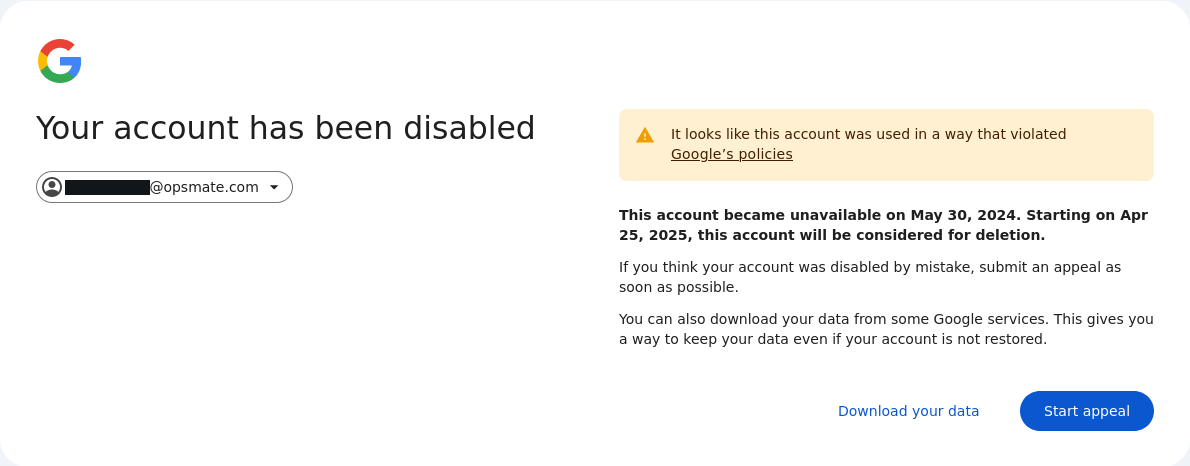
Although Google's customer support people were surprisingly responsive considering Google's rock-bottom reputation in this area, the process to recover our account was super frustrating:
-
Google required me to email them from the address associated with the account, but when I did so, the message was bounced with the error "The account [redacted] is disabled" (the redacted portion being the email address I sent from). When I emailed from a different address, the message went through, but the support people initially refused to communicate with it because it was the wrong address.
-
At one point Google asked me to provide the IDs of our Google Cloud projects - information which I could not retrieve because I couldn't log in to the console. Have you saved your project IDs in a safe place in case your account gets suspended?
-
After several emails back and forth with Google support, and verifying a phone number, I was able to log back into the Google Cloud console, but two of our projects were still suspended, including the one needed for the customer integrations. (At the time, we still had some domains registered through Google Cloud Domains, and thankfully the project for this was accessible, allowing me to begin transferring all of our domains out to a more dependable registrar.)
-
The day after I regained access to the console, I received an automated email from no-reply@accounts.google.com stating that my access to Google Cloud Platform had been restricted. Once again, I could no longer access the console, but the error message was different this time:
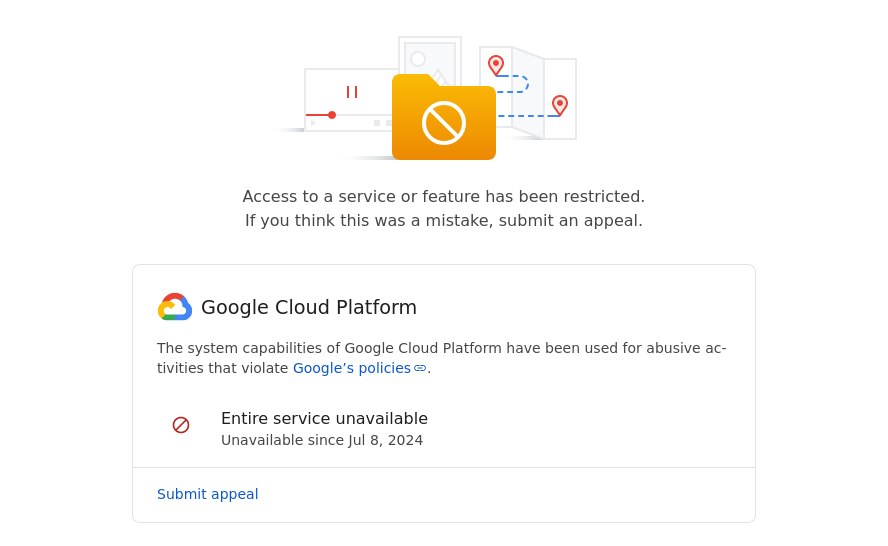
-
Twelve hours later, I received multiple automated emails from google-cloud-compliance@google.com stating that my Google Cloud projects had been "reinstated" but I still could not access the console.
-
Seven hours after that, I got another automated email from no-reply@accounts.google.com stating that my access to Google Cloud Platform had been restored. Everything began working after this.
I was never told why our account was suspended or what could be done to prevent it from happening again. Although Google claims to send emails when an account or project is suspended, they never did so for the initial suspension. Since errors with customer integrations were only being displayed in our customers' SSLMate consoles (usually an error indicates the customer made a mistake), I didn't learn about the suspension right away. I fixed this by adding a health check that fails if a large percentage of Google Cloud integrations have errors.
The Second Suspension
Two Fridays ago, that health check failed. I immediately investigated and saw that all but one Google Cloud integrations were failing with the same error as during last year's suspension ("Invalid grant: account not found"). Groaning, I tried logging into the Google Cloud console, bracing myself for another Kafkaesque reinstatement process. At least I know the project IDs this time, I reassured myself. Surprisingly, I was able to log in successfully. Then I got emails, one per Google Cloud project, informing me that my projects had been reinstated "based on information that [I] have provided." Naturally, I had received no emails that they had been suspended in the first place. The integrations started working again.
The Third Suspension
Last Friday, the health check failed again. I logged in to the Google Cloud console, unsure what to expect. This time, I was presented with a third type of error message:
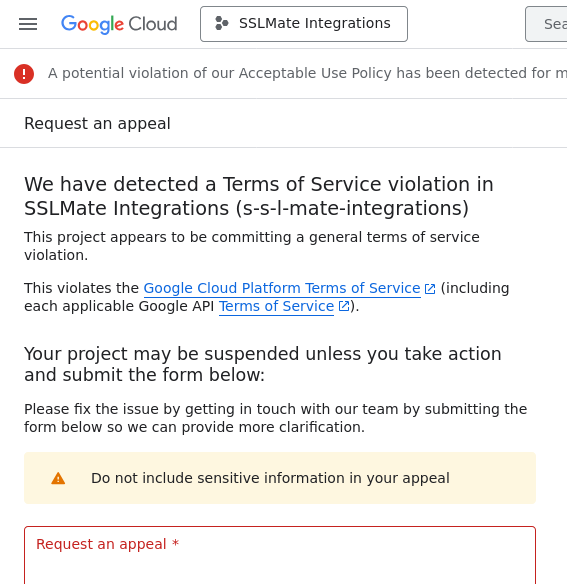
Most, but not all, of SSLMate's Google Cloud projects were suspended, including the one needed for customer integrations.
I submitted an appeal on Friday. On Sunday, I received an email from Google. Was it a response to the appeal? Nope! It was an automated email stating that SSLMate's access to Google Cloud was now completely suspended.
Edited to add: On Monday, shortly after this post hit the front page of Hacker News, most projects were reinstated, including the project for the integrations. A few hours later, access was fully restored. As before, there was no explanation why access was suspended or how to prevent it from happening again.
The Lucky Customer
Incredibly, we have one lucky customer whose integration has continued to work during every suspension, even though it uses a service account in the same suspended project as all the other customer integrations.
What Now?
Clearly, I cannot rely on having a Google account for production use cases. Google has built a complex, unreliable system in which some or all of the following can be suspended: an entire Google account, a Google Cloud Platform account, or individual Google Cloud projects.
Unfortunately, the alternatives for integrations are not great.
The first alternative is to ask customers to create a service account for SSLMate and have SSLMate authenticate to it using a long-lived key. This is pretty easy, but less secure since the long-lived key could leak and can never be rotated in practice.
The second alternative is to use OpenID Connect, aka OIDC. In recent years, OIDC has become the de facto standard for integrations between service providers. For example, you can use OIDC to let GitHub Actions access your Google Cloud account without the need for long-lived credentials. SSLMate's Azure integration uses OIDC and it works well.
Unfortunately, Google has made setting up OIDC unnecessarily difficult. What is currently a simple one step process for our customers to add an integration (assign some roles to a service account) would become a complicated seven step process:
- Enable the IAM Service Account Credentials API.
- Create a service account.
- Create a workload identity pool.
- Create a workload identity provider in the pool created in step 3.
- Allow SSLMate to impersonate the service account created in step 2 (this requires knowing the ID of the pool created in step 3).
- Assign roles to the service account created in step 2.
- Provide SSLMate with the ID of the service account created in step 2, and the ID of the workload identity provider created in step 4.
Since many of the steps require knowing the identifiers of resources created in previous steps, it's hard for SSLMate to provide easy-to-follow instructions.
This is more complicated than it needs to be:
Creating a service account (steps 1, 2, and 5) should not be necessary. While it is possible to forgo a service account and assign roles directly to an identity from the pool, not all Google Cloud services support this. If you want your integration to work with all current and future services, you have to impersonate a service account. Google should stop treating OIDC like a second-class citizen and guarantee that all current and future services will directly support it.
Creating an identity pool shouldn't be necessary either. While I'm sure some use cases are nicely served by pools, it seems like most setups are going to have just one provider per pool, making the extra step of creating a pool nothing but unnecessary busy work.
Even creating a provider shouldn't be necessary; it should be possible to assign roles directly to an OIDC issuer URL and subject. You should only have to create a provider if you need to do more advanced configuration, such as mapping attributes.
I find this state of affairs unacceptable, because it's really, really important to move away from long-lived credentials and Google ought to be doing everything possible to encourage more secure alternatives. Sadly, SSLMate's current solution of provider-created service accounts is susceptible to arbitrary account suspensions, and OIDC is hampered by an unnecessarily complicated setup process.
In summary, when setting up cross-provider access with Google Cloud, you can have only two of the following:
- No dangerous long-lived credentials.
- Easy for the customer to set up.
- Safe from arbitrary account suspensions.
| Provider-created service accounts | Service account + key | OpenID Connect |
|---|---|---|
| No long-lived keys | No long-lived keys | |
| Easy setup | Easy setup | |
| Safe from suspension | Safe from suspension |
Which two would you pick?