April 29, 2026
FastCGI: 30 Years Old and Still the Better Protocol for Reverse Proxies
HTTP reverse proxying is a minefield. Just the other week, a researcher disclosed a desync vulnerability in Discord's media proxy that allowed spying on private attachments. This is not unusual; these vulnerabilities just keep coming.
The problem is the widespread use of HTTP as the protocol between reverse proxies and backends, even though it's unfit for the job. But we don't have to use HTTP here. There's a 30-year-old protocol for proxy-to-backend communication that avoids HTTP's pitfalls. It's called FastCGI, and its specification was released 30 years ago today.
FastCGI is a Wire Protocol, not a Process Model
It's true that some web servers can automatically spawn FastCGI processes
to handle requests for files with the .fcgi extension, much like they
would for .cgi files. But you don't have to use FastCGI this way - you
can also use the FastCGI protocol just like HTTP, with requests sent
over a TCP or UNIX socket to a long-running daemon that handles them as if they
were HTTP requests.
For example, in Go all you have to do is import the
net/http/fcgi
standard library package and replace http.Serve with fcgi.Serve:
Go HTTP
l, _ := net.Listen("tcp", "127.0.0.1:8080")
http.Serve(l, handler)
Go FastCGI
l, _ := net.Listen("tcp", "127.0.0.1:8080")
fcgi.Serve(l, handler)
Everything else about your app stays the same - even your handler, which continues to use the standard
http.ResponseWriter and http.Request types.
Popular proxies like Apache, Caddy, nginx, and HAProxy support FastCGI backends, and the configuration is simple:
nginx HTTP
proxy_pass http://localhost:8080;
nginx FastCGI
fastcgi_pass localhost:8080;
include fastcgi_params;
Show more config examples
Apache HTTP
ProxyPass / http://localhost:8080/
Apache FastCGI
ProxyPass / fcgi://localhost:8080/
Caddy HTTP
reverse_proxy localhost:8080 {
transport http {
}
}
Caddy FastCGI
reverse_proxy localhost:8080 {
transport fastcgi {
}
}
HAProxy HTTP
backend app_backend
server s1 localhost:8080
HAProxy FastCGI
fcgi-app fcgi_app
docroot /
backend app_backend
use-fcgi-app fcgi_app
server s1 localhost:8080 proto fcgi
Why HTTP Sucks for Reverse Proxies: Desync Attacks / Request Smuggling
HTTP/1.1 has the tragic property of looking simple on the surface (it's just text!) but actually being a nightmare to parse robustly. There are so many different ways to format the same HTTP message, and there are too many edge cases and ambiguities for implementations to handle consistently. As a result, no two HTTP/1.1 implementations are exactly the same, and the same message can be parsed differently by different parsers.
The most serious problem is that there is no explicit framing of HTTP messages - the message itself describes where it ends, and there are multiple ways for a message to do that, all with their own edge cases. Implementations can disagree about where a message ends, and consequently, where the next message begins. This is the foundation of HTTP desync attacks, also known as request smuggling, wherein a reverse proxy and a backend disagree about the boundaries between HTTP messages, causing all sorts of nightmare security issues, such as the Discord vulnerability I linked above.
A lot of people seem to think you can just patch the parser divergences, but this is a losing strategy. James Kettle just keeps finding new ones. After finding another batch last year, he declared "HTTP/1.1 must die".
HTTP/2, when consistently used between the proxy and backend, fixes desync by putting clear boundaries around messages, but FastCGI has been doing that since 1996 with a simpler protocol. For context, nginx has supported FastCGI backends since its first release, but only got support for HTTP/2 backends in late 2025. Apache's support for HTTP/2 backends is still "experimental".
Why HTTP Sucks for Reverse Proxies: Untrusted Headers
If desync attacks were the only problem, you could just use HTTP/2 and call it a day. Unfortunately, there's another problem: HTTP has no robust way for the proxy to convey trusted information about the request, such as the real client IP address, authenticated username (if the proxy handles authentication), or client certificate details (if mTLS is used).
The only option is to stick this information in HTTP headers, alongside
the headers proxied from the client, without a clear structural distinction between trusted
headers from the proxy and untrusted headers from a potential attacker.
For example, the X-Real-IP header is often used
to convey the client's real IP address. In theory, if your proxy correctly deletes all instances
of the X-Real-IP header (not just the first, and including case variations like x-REaL-ip) before adding its own, you're safe.
In practice, this is a minefield
and there are an awful lot of ways your backend can end up trusting attacker-controlled data.
Your proxy really needs to delete not just X-Real-IP, but any header that's used for this sort of thing,
just in case some part of your stack relies on it without your knowledge.
For example, the Chi middleware determines the client's real IP address by looking at the
True-Client-IP header first. Only if True-Client-IP doesn't exist does it use X-Real-IP.
So even if your proxy does the right thing with X-Real-IP, you can still be pwned by an attacker
sending a True-Client-IP header.
FastCGI completely avoids this class of problem by providing domain separation between headers from the client and information added by the proxy. Though trusted data from the proxy and HTTP request headers are transmitted to the backend in the same key/value parameter list, HTTP header names are prefixed with the string "HTTP_", making it structurally impossible for clients to send a header that would be interpreted as trusted data.
FastCGI defines some standard parameters such as REMOTE_ADDR to convey the real client IP address.
Go's net/http/fcgi package automatically uses this parameter to populate the RemoteAddr field of http.Request,
rendering middleware unnecessary. It Just Works. Proxies can also use non-standard parameters to report whether HTTPS was used,
what TLS ciphersuite was negotiated, and what client certificate was presented, if any.
Go automatically sets the Request's TLS field to a non-nil (but empty) value if the request used HTTPS,
which is very handy for enforcing the use of HTTPS. The fcgi.ProcessEnv function can be used to access the full set of
trusted parameters sent by the proxy.
Closing Thoughts
If FastCGI is the better protocol, why isn't it more popular? Maybe it's the name - while capitalizing on CGI's popularity made sense in 1996, CGI feels dated in 2026. There's also an enduring lack of awareness of the security problems with HTTP reverse proxying. Watchfire described desync attacks in 2005, and gave a prescient warning of their intractability, but the attacks were inexplicably ignored for over a decade. In an alternate timeline, Watchfire's research was taken seriously and people went looking for other protocols for reverse proxies.
FastCGI is very usable today, and has been in production use at SSLMate for over 10 years. That said, using a vintage technology has some downsides. It was never updated to support WebSockets. The tooling is not as good. For example, curl has no way to make requests to a FastCGI server. It supports FTP, Gopher, and even SMTP (however that works), but not FastCGI. When I benchmarked Go's FastCGI server behind a variety of reverse proxies, some workloads had worse throughput compared to HTTP/1.1 or HTTP/2. I don't think that's inherent to the protocol, but a reflection that FastCGI code paths have not been optimized as much as HTTP.
Despite these shortcomings, I still think FastCGI is worth using. I don't use WebSockets, and it's fast enough for my use case (and maybe yours too). If it ever became the bottleneck, I'd rather buy more hardware than deal with the nightmare of HTTP reverse proxying.
Happy 30th birthday, FastCGI!
February 19, 2026
Why IP Address Certificates Are Dangerous and Usually Unnecessary
Imagine you're connecting to an IP address over TLS. The server presents a valid, properly-issued IP address certificate from a publicly-trusted certificate authority. But you're not really talking to that IP address, but to a man-in-the-middle (MitM) who was assigned the IP address over a year ago. How could this be? Unfortunately, publicly-trusted IP address certificates just don't provide the same level of security as certificates for domain names. Unless you're operating a DNS-over-TLS or DNS-over-HTTPS resolver, you should not use IP address certificates. You'll be much more secure with domain name certificates.
TL;DR:
- A "valid" IP address certificate can mean "someone who controlled this IP address any time in the last 796 days."
- Certificate validation happens in the past, not at connection time, and IP addresses are reused constantly.
- This risk exists for domains too, but it's far worse for IP addresses, especially in cloud environments.
- IP address certificates only make sense for DNS-over-TLS and DNS-over-HTTPS resolvers.
- For everything else, use domain name certificates; even short-lived servers can do this practically by embedding IP addresses in hostnames.
(When I say IP address certificate, I mean a TLS certificate with an IP address subjectAltName, which allows a certificate to authenticate a connection to an IP address, rather than a domain name as is typical on the Web. Public certificate authorities have been allowed to issue IP address certificates for a long time, but I fear they will become more popular since Let's Encrypt added support for them last month.)
The basic security property provided by a certificate is that the certificate authority has validated that the certificate subscriber (the person who applies for the certificate and knows its private key) is authorized to represent the domain name or IP address in the certificate. This ensures that the other end of a TLS connection is truly the domain or IP address that you want to connect to, not a MitM impostor.
But the validation is not done every time a TLS connection is established; rather, it was done at some point in the past. Thus, the certificate subscriber may no longer be authorized to represent the domain or IP address.
How old might the validation be? As of February 2026, certificate authorities are allowed to issue certificates that are valid for up to 398 days. (Let's Encrypt limits their IP address certs to 6 days, but you have to worry about attackers using other CAs, not just the CA you use.) So the validation may be 398 days old. But it gets worse. When issuing a certificate, CAs are allowed to rely on a validation that was done up to 398 days prior to issuance. So when you establish a TLS connection, you may be relying on a validation that was performed a whopping 796 days ago. You could be talking not to the current assignee of the domain or IP address, but to anyone who was assigned the domain or IP address at any point in the last 2+ years.
This is a problem with both domains and IP addresses, but it's way worse with IP addresses. While it's still very possible to register a domain that no one has ever registered before, you don't have this luxury with IPv4 addresses. There are no unassigned IPv4 addresses left; when you get an IPv4 address, it has already been assigned to someone else. In some cases, particularly in cloud environments, the address could have had as many tenants as a room at a Motel 6.
For some use cases, the risk is unavoidable. For example, DNS-over-TLS and DNS-over-HTTPS resolvers have to be contacted by IP address, to avoid a circular dependency on DNS resolution. Domain name certificates are not an option. Fortunately, by 2029, the maximum certificate lifetime will be 47 days, and the maximum validation reuse period will be 10 days, so the risk window will be only 57 days. That's not too bad for a service that's likely to exist for many years with the same IP address.
But even with a 57 day window, other use cases should just use domain name certificates. One use case for IP address certificates is particularly misguided: securing short-lived cloud workloads. Let's Encrypt describes this use case as:
Securing ephemeral connections within cloud hosting infrastructure, like connections between one back-end cloud server and another, or ephemeral connections to administer new or short-lived back-end servers via HTTPS - as long as those servers have at least one public IP address available.
On Bluesky, Ryan Hurst goes into more detail:
Modern infrastructure no longer has stable hostnames, static IPs, or long-lived trust anchors. Workloads spin up before DNS exists, live briefly, and disappear. Trust has to keep up.
Short-lived and IP certificates make it possible to use TLS before a DNS name exists, reduce friction for DNS over HTTPS adoption, secure ephemeral devices and services by default, and shift trust from long-lived credentials to automated renewal.
As I understand it, the use case is running servers which accept TLS connections and exist for a very short period, like minutes. The most secure implementation would be to assign the server a unique, never-before-used hostname under your domain, publish a DNS record pointing the hostname to the server's IP address, get a domain name certificate, and have clients connect to the hostname. Thanks to the unique hostname, clients can be sure they're connecting to the right server and not to an impostor who was assigned the IP address at some point in the past.
But Ryan suggests that it might not be possible to wait for a DNS record to be published before the server needs to be usable. Fortunately, it's still possible to avoid IP address certificates. Instead, you can publish, in advance, a DNS record under your domain for every IP address you might need to use. For example, ip-192-0-2-1.yourcompany.example would resolve to 192.0.2.1. ISPs commonly publish DNS records like this for their entire IP address space, so it's possible to do at scale. Have your clients connect to your short-lived server using this DNS record, rather than an IP address. To prevent would-be attackers from completing domain validation under your domain using a non-DNS validation method, you should also publish a CAA record for your domain that uses ACME account binding to restrict issuance to your ACME account. Now clients can be sure they're connecting to a server controlled by your organization, rather than anyone who happened to be assigned the same cloud IP address in the last 2 years.
You can also monitor Certificate Transparency logs to look for unauthorized certificates for your domain. Monitoring Certificate Transparency is not practical when using IP address certificates with short-lived cloud workloads, since the set of IP addresses that you need to monitor will be constantly changing as you create and destroy your servers, and it will be hard to tell whether an unknown certificate is malicious or just an innocent issuance to someone who got assigned the same IP address.
I encourage you to think long and hard before using IP address certificates, especially for short-lived cloud servers. The high risk of stale validation, combined with the inability to effectively monitor Certificate Transparency, bring IP address certificates uncomfortably close to opportunistic encryption (TLS without certificate validation), even with post-2029 shortened lifetimes. Fortunately, you can embed IP addresses in pre-published DNS records if you can't publish DNS records on the fly. Doing a little extra DNS work is a small price to pay for avoiding the inherent risks of IP address certificates.
December 10, 2025
Certificate Authorities Are Once Again Issuing Certificates That Don't Work
Twice a year, the Certificate Transparency ecosystem undergoes a transition as certificate authorities start to submit certificates to new semiannual log partitions. And recently, the ecosystem has started transitioning to the new static-ct-api specification. Unfortunately, despite efforts to make these transitions extremely easy for certificate authorities, in the past week I have detected 16 certificate authorities who have bungled these transitions, issuing certificates that are rejected by some or all mainstream web browsers with an error message like "This Connection Is Not Private" or ERR_CERTIFICATE_TRANSPARENCY_REQUIRED.
If you're not familiar, Certificate Transparency (CT) is a system for publishing SSL certificates in public logs. Certificate Transparency monitors like Cert Spotter download the logs to help you track certificate expiration and detect unauthorized certificates for your domains.
At a high level, Certificate Transparency works like this:
- Before issuing a certificate, the certificate authority (CA) creates a "precertificate" containing the details of the certificate it intends to issue.
- The CA submits the precertificate to multiple Certificate Transparency logs.
- Each log returns a receipt, called a Signed Certificate Timestamp (SCT), which confirms submission of the precertificate.
- The CA embeds the SCTs in the certificate which it gives to the site operator.
- When a browser loads a website, it makes sure the website's certificate has SCTs from a sufficient number of recognized logs. If it doesn't, the browser throws up an error page and refuses to load the website.
Billions of SSL certificates are issued and logged to CT every year. To prevent logs from growing indefinitely, logs only accept (pre)certificates which expire within a certain range, typically six months long. Every log will eventually contain only expired certificates, allowing it to be shut down. Meanwhile, new logs are created to contain certificates expiring further in the future.
How do CAs know what logs to submit precertificates to? It's easy: Apple and Chrome each publish a JSON file containing a list of logs. (Firefox and Edge use Chrome's list.) Apple's is at https://valid.apple.com/ct/log_list/current_log_list.json and Chrome's is at https://www.gstatic.com/ct/log_list/v3/log_list.json. Each log object contains the log's name, URL, public key, range of expiration dates accepted by the log, and crucially, the log's state.
{
"description": "Sectigo 'Elephant2027h1'",
"log_id": "YEyar3p/d18B1Ab8kg3ImesLHH34yVIb+voXdzuXi8k=",
"key": "MFkwEwYHKoZIzj0CAQYIKoZI...AScw2woA==",
"url": "https://elephant2027h1.ct.sectigo.com/",
"mmd": 86400,
"state": {
"usable": {
"timestamp": "2025-07-22T01:33:20Z"
}
},
"temporal_interval": {
"start_inclusive": "2027-01-01T00:00:00Z",
"end_exclusive": "2027-07-01T00:00:00Z"
}
}
The state is very simple: if it's "usable", then CAs should use it. If it's something else, CAs should not use it.
The full process of logging is a bit more complicated, because CAs have to include SCTs from a sufficiently-diverse set of logs, but when it comes to finding the initial set of logs to consider, it's hard to imagine how it could be any easier for CAs. They just need to download the Apple and Chrome lists and find the logs whose state is Usable in both lists and whose expiration range covers the expiration date of the certificate.
Despite this, a number of CAs appear to either disregard the state or only consider Chrome's log list. Historically, this has not caused problems because new logs have become Usable in both Chrome and Apple before they were needed for new certificates. Since the maximum certificate lifetime is 398 days, logs for certificates expiring in the first half of 2027 (2027h1) needed to be Usable by November 29, 2025. Unfortunately, not all 2027h1 logs were Usable by this date.
First, Google's 2027h1 logs (Argon 2027h1 and Xenon 2027h1) were added to Chrome 40 days later than they should have been. Normally, new logs are added to Chrome after 30 days of successful monitoring, but this process is still very manual and human error led to Chrome setting a 70 day timer instead of a 30 day timer. Consequentially, these logs are still in the Qualified state in Chrome. Although Qualified logs are recognized by up-to-date installations of Chrome (and Firefox and Edge), there may be out-of-date installations which do not recognize them, making it a very bad idea for CAs to use Qualified logs if they care about compatibility. Chrome, Firefox, and Edge automatically disable Certificate Transparency enforcement once they become 70 days out-of-date, so Argon and Xenon 2027h1 will become Usable on December 27, 2025, which is 70 days after they became Qualified. (Argon and Xenon 2027h1 are already Usable in Apple's list.)
Second, DigiCert's 2027h1 logs (Sphinx 2027h1 and Wyvern 2027h1) don't appear at all in Apple's log list. Since Apple doesn't use a public bug tracker for their CT log program like Chrome, I have no idea what went wrong. Did DigiCert forget to tell Apple about their new logs, or is Apple slow-rolling them for some reason? Certificates which rely on either DigiCert log won't work at all on Apple platforms. (They are already Usable in Chrome's list.)
While the late addition of logs is not ideal, it should not have been a problem, because there are plenty of other 2027h1 logs which became Usable for both Apple and Chrome in time.
I first became aware of issues last Tuesday when Arabella Barks posted a message to Mozilla's dev-security-policy mailing list referencing a certificate issued by Certum with SCTs from DigiCert Wyvern 2027h1. Sensing that this could be a widespread problem, I decided to investigate. My company, SSLMate, maintains a 51TB PostgreSQL database with the contents of every Certificate Transparency log. The database's primary purpose is to power our Certificate Transparency monitoring service, Cert Spotter, and our Certificate Transparency Search API, but it's also very handy for investigating ecosystem issues.
I ran a query to find all precertificates logged to Google's and DigiCert's 2027h1 logs. This alone was not sufficient to identify broken certificates, since CAs could be submitting precertificates to these logs but not including the SCTs in the final certificate, or including more than the minimum number of required SCTs. Therefore, for every precertificate, I looked to see if the corresponding final certificate had been logged anywhere. If it had, I ran it through SSLMate's CT Policy Analyzer to see if it had enough SCTs from broadly Usable logs. If the final certificate wasn't available for analysis, I counted how many other logs the precertificate was logged to. If fewer than three of these logs were Usable, then there was no way the corresponding certificate could have enough SCTs.
I posted my findings to the ct-policy mailing list later that day, alerting CAs to the problem. Since then, I've found even more certificates relying on logs that are not broadly Usable. As of publication time, the following CAs have issued such certificates:
- Certum
- Cybertrust Japan (fixed)
- Disig
- GDCA
- GlobalSign (fixed)
- HARICA
- IdenTrust (fixed)
- Izenpe (fixed)
- Microsec
- NAVER
- SECOM
- SSL.com
- SHECA
- TWCA (fixed)
- certSIGN
- emSign
Of those, only the five indicated above have fixed their systems. The others have all issued broken certificates within the last two days, even though it has been a week since my first public posting.
Unfortunately, logging to non-Usable logs wasn't the only problem. Last Wednesday, Cert Spotter began alerting me about certificates issued by Cybertrust Japan containing SCTs with invalid signatures. I noticed that the SCTs with invalid signatures were all from static-ct-api logs.
To address shortcomings with the original Certificate Transparency specification (RFC6962), the ecosystem has been transitioning to logs based on the static-ct-api specification. Almost half of the 2027h1 logs use static-ct-api. However, while static-ct-api requires major changes for log monitors, it uses the exact same protocol for CAs to submit (pre)certificates. This was an intentional decision to make static-ct-api easier to adopt, so that it wouldn't suffer the same fate as RFC9162, which was intended to replace RFC6962 but was dead-on-arrival in part because it completely broke compatibility with the existing ecosystem.
However, there is one teeny tiny difference with static-ct-api: whereas RFC6962 logs always return SCTs with an empty extensions field, static-ct-api logs return SCTs with non-empty extensions. This should not be problem - the extensions field is just an opaque byte array and CAs do not need to understand what static-ct-api logs place it in it. They just need to copy it through to the final certificate, which they should have been doing anyways with RFC6962 logs. But Cybertrust Japan was always leaving the extension field empty regardless of what the log returned, breaking the SCT's signature. Since SCTs with invalid signatures are disregarded by browsers, this left their certificates with an insufficient number of SCTs, dooming them to rejection.
After publication of this post, Cert Spotter alerted me to invalid SCT signatures
in certificates issued by NAVER. In this case, the SCT extensions were non-empty but
encoded in base64, indicating that NAVER wasn't decoding the base64 from the JSON response
when copying it to the SCT. On one hand, I don't love
RFC6962's wording about the extensions
field:
while the other JSON fields, like id and signature, are clearly indicated
as "base64 encoded", it's only implied that extensions is base64-encoded (it says "Clients
should decode the base64-encoded data and include it in the SCT"). On the other hand,
if NAVER were verifying the signature of SCTs before embedding them in certificates, they almost certainly would have caught
this mistake, since successful verification relies on correctly decoding the JSON response.
And we know from past incidents
that it's very important for CAs to verify SCT signatures.
Unfortunately, we'll probably never learn the root cause of these failures or what CAs are doing to prevent them from happening again. Normally, when a CA violates a policy, they are required to publish a public incident report, answer questions from the community, and note the failure in their next audit. If their incident response is bad or they keep having the same incident, they run the risk of being distrusted. However, Certificate Transparency is not a policy requirement in the traditional sense - CAs are free to issue certificates which violate CT requirements; those certificates just won't work in CT-enforcing browsers. This allows to CAs to issue unlogged certificates to customers who don't want their certificates to be public knowledge (and don't need them to work in browsers). Of course, that's not what the CAs here were doing - they were clearly trying to issue certificates that work in browsers; they just did a bad job of it.
Previously:
November 3, 2025
Google Just Suspended My Company's Google Cloud Account for the Third Time
On each of the last two Fridays, Google has suspended SSLMate's Google Cloud access without notification, having previously suspended it in 2024 without notification. But this isn't just another cautionary tale about using Google Cloud Platform; it's also a story about usable security and how Google's capriciousness is forcing me to choose between weakening security or reducing usability.
Apart from testing and experimentation, the only reason SSLMate still has a Google Cloud presence is to enable integrations with our customers' Google Cloud accounts so that we can publish certificate validation DNS records and discover domain names to monitor on their behalf. We create a service account for each customer under our Google Cloud project, and ask the customer to authorize this service account to access Cloud DNS and Cloud Domains. When SSLMate needs to access a customer's Google Cloud account, it impersonates the corresponding service account. I developed this system based on a suggestion in Google's own documentation (under "How can I access data from my users' Google Cloud project using Cloud APIs?") and it works really well. It is both very easy for the customer to configure, and secure: there are no long-lived credentials or confused deputy vulnerabilities.
Easy and secure: I love it when that's possible!
The only problem is that Google keeps suspending our Google Cloud access.
The First Suspension
Google suspended us for the first time in 2024. Our customer integrations began failing, and logging into the Google Cloud console returned this error:
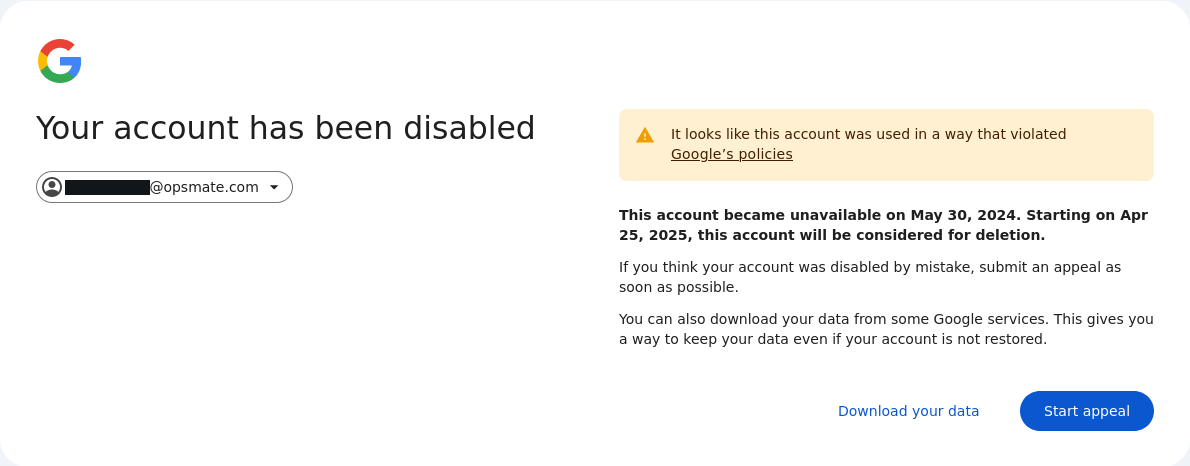
Although Google's customer support people were surprisingly responsive considering Google's rock-bottom reputation in this area, the process to recover our account was super frustrating:
-
Google required me to email them from the address associated with the account, but when I did so, the message was bounced with the error "The account [redacted] is disabled" (the redacted portion being the email address I sent from). When I emailed from a different address, the message went through, but the support people initially refused to communicate with it because it was the wrong address.
-
At one point Google asked me to provide the IDs of our Google Cloud projects - information which I could not retrieve because I couldn't log in to the console. Have you saved your project IDs in a safe place in case your account gets suspended?
-
After several emails back and forth with Google support, and verifying a phone number, I was able to log back into the Google Cloud console, but two of our projects were still suspended, including the one needed for the customer integrations. (At the time, we still had some domains registered through Google Cloud Domains, and thankfully the project for this was accessible, allowing me to begin transferring all of our domains out to a more dependable registrar.)
-
The day after I regained access to the console, I received an automated email from no-reply@accounts.google.com stating that my access to Google Cloud Platform had been restricted. Once again, I could no longer access the console, but the error message was different this time:
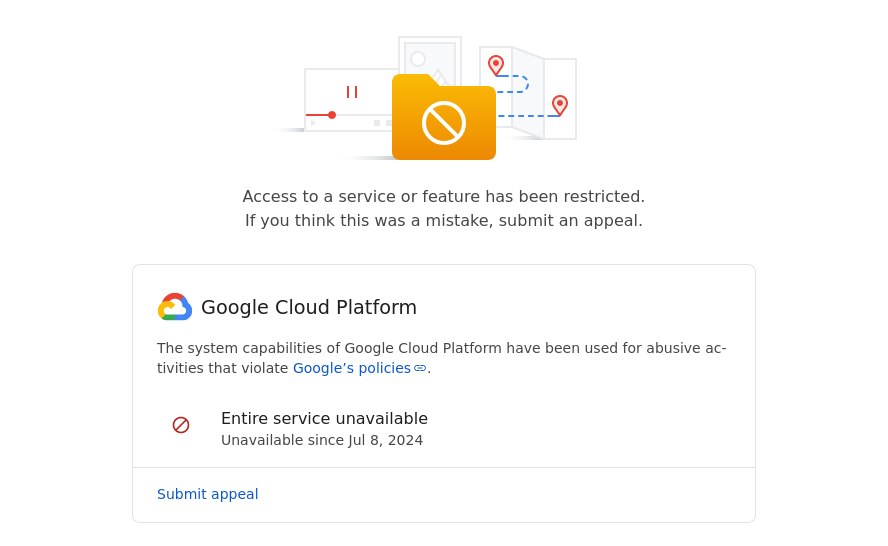
-
Twelve hours later, I received multiple automated emails from google-cloud-compliance@google.com stating that my Google Cloud projects had been "reinstated" but I still could not access the console.
-
Seven hours after that, I got another automated email from no-reply@accounts.google.com stating that my access to Google Cloud Platform had been restored. Everything began working after this.
I was never told why our account was suspended or what could be done to prevent it from happening again. Although Google claims to send emails when an account or project is suspended, they never did so for the initial suspension. Since errors with customer integrations were only being displayed in our customers' SSLMate consoles (usually an error indicates the customer made a mistake), I didn't learn about the suspension right away. I fixed this by adding a health check that fails if a large percentage of Google Cloud integrations have errors.
The Second Suspension
Two Fridays ago, that health check failed. I immediately investigated and saw that all but one Google Cloud integrations were failing with the same error as during last year's suspension ("Invalid grant: account not found"). Groaning, I tried logging into the Google Cloud console, bracing myself for another Kafkaesque reinstatement process. At least I know the project IDs this time, I reassured myself. Surprisingly, I was able to log in successfully. Then I got emails, one per Google Cloud project, informing me that my projects had been reinstated "based on information that [I] have provided." Naturally, I had received no emails that they had been suspended in the first place. The integrations started working again.
The Third Suspension
Last Friday, the health check failed again. I logged in to the Google Cloud console, unsure what to expect. This time, I was presented with a third type of error message:
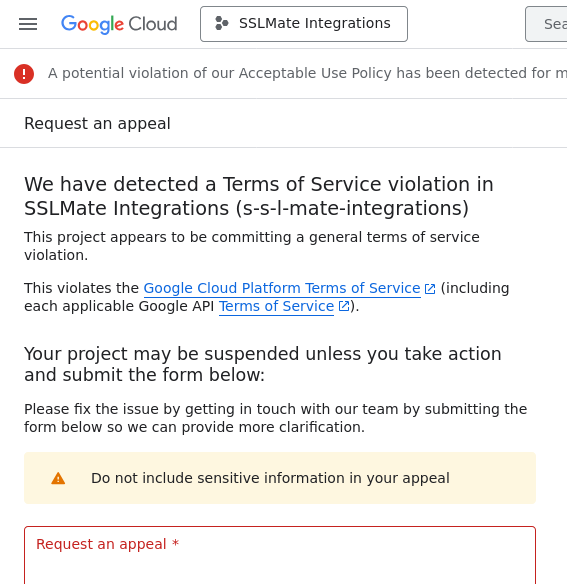
Most, but not all, of SSLMate's Google Cloud projects were suspended, including the one needed for customer integrations.
I submitted an appeal on Friday. On Sunday, I received an email from Google. Was it a response to the appeal? Nope! It was an automated email stating that SSLMate's access to Google Cloud was now completely suspended.
Edited to add: On Monday, shortly after this post hit the front page of Hacker News, most projects were reinstated, including the project for the integrations. A few hours later, access was fully restored. As before, there was no explanation why access was suspended or how to prevent it from happening again.
The Lucky Customer
Incredibly, we have one lucky customer whose integration has continued to work during every suspension, even though it uses a service account in the same suspended project as all the other customer integrations.
What Now?
Clearly, I cannot rely on having a Google account for production use cases. Google has built a complex, unreliable system in which some or all of the following can be suspended: an entire Google account, a Google Cloud Platform account, or individual Google Cloud projects.
Unfortunately, the alternatives for integrations are not great.
The first alternative is to ask customers to create a service account for SSLMate and have SSLMate authenticate to it using a long-lived key. This is pretty easy, but less secure since the long-lived key could leak and can never be rotated in practice.
The second alternative is to use OpenID Connect, aka OIDC. In recent years, OIDC has become the de facto standard for integrations between service providers. For example, you can use OIDC to let GitHub Actions access your Google Cloud account without the need for long-lived credentials. SSLMate's Azure integration uses OIDC and it works well.
Unfortunately, Google has made setting up OIDC unnecessarily difficult. What is currently a simple one step process for our customers to add an integration (assign some roles to a service account) would become a complicated seven step process:
- Enable the IAM Service Account Credentials API.
- Create a service account.
- Create a workload identity pool.
- Create a workload identity provider in the pool created in step 3.
- Allow SSLMate to impersonate the service account created in step 2 (this requires knowing the ID of the pool created in step 3).
- Assign roles to the service account created in step 2.
- Provide SSLMate with the ID of the service account created in step 2, and the ID of the workload identity provider created in step 4.
Since many of the steps require knowing the identifiers of resources created in previous steps, it's hard for SSLMate to provide easy-to-follow instructions.
This is more complicated than it needs to be:
Creating a service account (steps 1, 2, and 5) should not be necessary. While it is possible to forgo a service account and assign roles directly to an identity from the pool, not all Google Cloud services support this. If you want your integration to work with all current and future services, you have to impersonate a service account. Google should stop treating OIDC like a second-class citizen and guarantee that all current and future services will directly support it.
Creating an identity pool shouldn't be necessary either. While I'm sure some use cases are nicely served by pools, it seems like most setups are going to have just one provider per pool, making the extra step of creating a pool nothing but unnecessary busy work.
Even creating a provider shouldn't be necessary; it should be possible to assign roles directly to an OIDC issuer URL and subject. You should only have to create a provider if you need to do more advanced configuration, such as mapping attributes.
I find this state of affairs unacceptable, because it's really, really important to move away from long-lived credentials and Google ought to be doing everything possible to encourage more secure alternatives. Sadly, SSLMate's current solution of provider-created service accounts is susceptible to arbitrary account suspensions, and OIDC is hampered by an unnecessarily complicated setup process.
In summary, when setting up cross-provider access with Google Cloud, you can have only two of the following:
- No dangerous long-lived credentials.
- Easy for the customer to set up.
- Safe from arbitrary account suspensions.
| Provider-created service accounts | Service account + key | OpenID Connect |
|---|---|---|
| No long-lived keys | No long-lived keys | |
| Easy setup | Easy setup | |
| Safe from suspension | Safe from suspension |
Which two would you pick?
October 29, 2025
I'm Independently Verifying Go's Reproducible Builds
When you try to compile a Go module that requires a newer version of the Go toolchain than the one you have installed, the go command automatically downloads the newer toolchain and uses it for compiling the module. (And only that module; your system's go installation is not replaced.) This useful feature was introduced in Go 1.21 and has let me quickly adopt new Go features in my open source projects without inconveniencing people with older versions of Go.
However, the idea of downloading a binary and executing it on demand makes a lot of people uncomfortable. It feels like such an easy vector for a supply chain attack, where Google, or an attacker who has compromised Google or gotten a misissued SSL certificate, could deliver a malicious binary. Many developers are more comfortable getting Go from their Linux distribution, or compiling it from source themselves.
To address these concerns, the Go project did two things:
They made it so every version of Go starting with 1.21 could be easily reproduced from its source code. Every time you compile a Go toolchain, it produces the exact same Zip archive, byte-for-byte, regardless of the current time, your operating system, your architecture, or other aspects of your environment (such as the directory from which you run the build).
They started publishing the checksum of every toolchain Zip archive in a public transparency log called the Go Checksum Database. The go command verifies that the checksum of a downloaded toolchain is published in the Checksum Database for anyone to see.
These measures mean that:
You can be confident that the binaries downloaded and executed by the go command are the exact same binaries you would have gotten had you built the toolchain from source yourself. If there's a backdoor, the backdoor has to be in the source code.
You can be confident that the binaries downloaded and executed by the go command are the same binaries that everyone else is downloading. If there's a backdoor, it has to be served to the whole world, making it easier to detect.
But these measures mean nothing if no one is checking that the binaries are reproducible, or that the Checksum Database isn't presenting inconsistent information to different clients. Although Google checks reproducibility and publishes a report, this doesn't help if you think Google might try to slip in a backdoor themselves. There needs to be an independent third party doing the checks.
Why not me? I was involved in Debian's Reproducible Builds project back in the day and developed some of the core tooling used to make Debian packages reproducible (strip-nondeterminism and disorderfs). I also have extensive experience monitoring Certificate Transparency logs and have detected misbehavior by numerous logs since 2017. And I do not work for Google (though I have eaten their food).
In fact, I've been quietly operating an auditor for the Go Checksum Database since 2020 called Source Spotter (à la Cert Spotter, my Certificate Transparency monitor). Source Spotter monitors the Checksum Database, making sure it doesn't present inconsistent information or publish more than one checksum for a given module and version. I decided to extend Source Spotter to also verify toolchain reproducibility.
The Checksum Database was originally intended for recording the checksums of Go modules.
Essentially, it's a verifiable, append-only log of records which say that a particular
version (e.g. v0.4.0) of a module (e.g. src.agwa.name/snid) has a particular SHA-256 hash. Go repurposed
it for recording toolchain checksums. Toolchain records have the pseudo-module
golang.org/toolchain and versions that look like v0.0.1-goVERSION.GOOS-GOARCH. For example, the Go1.24.2 toolchain for linux/amd64 has the module version v0.0.1-go1.24.2.linux-amd64.
When Source Spotter sees a new version of the golang.org/toolchain pseudo-module,
it downloads the corresponding source code, builds it in an AWS Lambda function by running make.bash -distpack,
and compares the checksum
of the resulting Zip file to the checksum published in the Checksum Database. Any mismatches
are published on a webpage and
in an Atom feed which I monitor.
So far, Source Spotter has successfully reproduced every toolchain since Go 1.21.0, for every architecture and operating system. As of publication time, that's 2,672 toolchains!
Bootstrap Toolchains
Since the Go toolchain is written in Go, building it requires an earlier version of the Go toolchain to be installed already.
When reproducing Go 1.21, 1.22, and 1.23, Source Spotter uses a Go 1.20.14 toolchain that I built from source. I started by building Go 1.4.3 using a C compiler. I used Go 1.4.3 to build Go 1.17.13, which I used to build Go 1.20.14. To mitigate Trusting Trust attacks, I repeated this process on both Debian and Amazon Linux using both GCC and Clang for the Go 1.4 build. I got the exact same bytes every time, which I believe makes a compiler backdoor vanishingly unlikely. The scripts I used for this are open source.
When reproducing Go 1.24 or higher, Source Spotter uses a binary toolchain downloaded from the Go module proxy that it previously verified as being reproducible from source.
Problems Encountered
Compared to reproducing a typical Debian package, it was really easy to reproduce the same bytes when building the Go toolchains. Nevertheless, there were some bumps along the way:
First, the Darwin (macOS) toolchains published by Google contain signatures produced by Google's private key.
Obviously, Source Spotter can't reproduce these. Instead, Source Spotter has to download
the toolchain (making sure it matches the checksum published in the Checksum Database) and strip the signatures
to produce a new checksum that is verified against the reproduced toolchain.
I reused code written by Google
to strip the signatures and I honestly have no clue what it's doing and whether
it could potentially strip a backdoor. A review from someone versed in Darwin binaries would be very helpful!
Edit: since publication, I've learned enough about Darwin binaries to be confident in this code.
Second, to reproduce the linux-arm toolchains, Source Spotter has
to set GOARM=6 in the environment... except when reproducing Go 1.21.0, which
Google accidentally built using GOARM=7.
I find it unfortunate that cmd/dist (the tool used to build the toolchain) doesn't set this environment variable along with the many other environment variables it sets, but Russ Cox pointed me to some context why this is the case.
Finally, the Checksum Database contains a toolchain for Go 1.9.2rc2, which is not a valid version number. It turns out this version was released by mistake. To avoid raising an error for an invalid version number, Source Spotter has to special case it. Not a huge deal, but I found it interesting because it demonstrates one of the downsides of transparency logs: you can't fix or remove entries that were added by mistake!
Source Code Transparency
The source tarballs built by Source Spotter are not published in the Checksum Database, meaning Google could serve Source Spotter, and only Source Spotter, source code which contains a backdoor. To mitigate this, Source Spotter publishes the checksums of every source tarball it builds. However, there are alternatives:
First, Russ Cox pointed out that while the source tarballs aren't in the Checksum Database, the toolchain Zip archives also contain the source code, so Source Spotter could build those instead of the source tarballs. (A previous version of this post incorrectly said that source code wasn't published in the Checksum Database at all.)
Second, Filippo Valsorda suggested that Source Spotter build from Go's Git repository
and publish the Git commit IDs instead, since lots of Go developers have the Go Git repository checked out
and it would be relatively easy for them to compare the state of their repos against what Source Spotter has seen.
Regrettably, Git commit IDs are SHA-1, but this is mitigated by Git's use of
Marc Stevens' collision detection,
so the benefits may be worth the risk.
I think building from Git is a good idea, and to bootstrap it, Filippo used Magic Wormhole to send me the output of git show-ref --tags from his repo while we were both
at the Transparency.dev Summit last week.
Conclusion
Thanks to Go's Checksum Database and reproducible toolchains, Go developers get the usability benefits of a centralized package repository and binary toolchains without sacrificing the security benefits of decentralized packages and building from source. The Go team deserves enormous credit for making this a reality, particularly for building a system that is not too hard for a third party to verify. They've raised the bar, and I hope other language and package ecosystems can learn from what they've done.
Learn more by visiting the Source Spotter website or the GitHub repo.