December 18, 2012
Insecure and Inconvenient: Gmail's Broken Certificate Validation
Gmail has a feature to periodically fetch mail from POP accounts into your Gmail account. Although Gmail supports POP over SSL, for a long time Gmail did not check the validity of the POP server's SSL certificate. This was a security flaw: an active attacker could pull off a man-in-the-middle attack and intercept the POP traffic by presenting a bogus certificate. This was something that needed to be fixed, though in practice the likelihood of an active attack between the Gmail servers and your POP server was probably very low, much lower than the chance of an active attack between your laptop in a coffee shop and your POP server.
This month they decided to fix the problem, and their help now states:
Gmail uses "strict" SSL security. This means that we'll always enforce that your other provider's remote server has a valid SSL certificate. This offers a higher level of security to better protect your information.
Unfortunately, some cursory testing reveals that this "strict" security falls short and does nothing to prevent active attacks. While Gmail properly rejects self-signed certificates, it does not verify that the certificate's common name matches the server's hostname. Even if Gmail thinks it's connecting to alice.com's POP server, it will blindly accept a certificate for mallory.com, as long as it's signed by a recognized certificate authority. Consequentially, an attacker can still successfully pull off a man-in-the-middle attack by purchasing a certificate for his own domain and using it in the attack.
As an example, here's the error message you receive when you try to use an invalid username and password with a server using a self-signed certificate (note: since this article was written, this server no longer uses a self-signed certificate so you can't reproduce with this particular hostname):
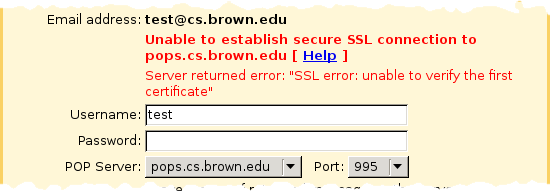
In contrast, here's what you get when you try to use an invalid username and password with a server using a properly-signed but misnamed certificate. It's not a certificate error from Gmail, but an authentication error from the server (meaning the password has already been transmitted):

The certificate's common name is really techhouse.org, not techhouse.brown.edu, which we can verify using the openssl command:
$ openssl s_client -connect techhouse.brown.edu:995
...
subject=/C=US/postalCode=02912/ST=Rhode Island/L=Providence/street=Box 6820 Brown University/O=Technology House/OU=TH Server/OU=Provided by DNC Holdings, Inc./OU=Direct NIC Pro SSL/CN=techhouse.org
issuer=/C=GB/ST=Greater Manchester/L=Salford/O=COMODO CA Limited/CN=COMODO High-Assurance Secure Server CA
...
Furthermore, while this change does absolutely nothing to improve security, it seriously inconveniences users who want to connect to POP servers with self-signed certificates. There is no way to override certificate errors, which means that users who are willing to accept the low risk of an active attack in exchange for saving some money on a "real" certificate are out of luck. Insultingly, plain text POP is still an option, so Google can't claim to be protecting users from themselves. While self-signed certificates are verboten, transmitting your password and mail in the clear on the Internet where it can be passively eavesdropped is just fine.
So Google has made the whole situation worse and not one iota better. But more troubling, it shows that not even Google can get this right all the time, which reduces my confidence not only in the overall security of Google's services, but also in the ability of people who aren't Google to do this properly. Certificate validation bugs like forgetting to check the common name are all too common and were the subject of a great paper recently published titled "The most dangerous code in the world." If you want to learn more, especially if you think you might ever program with SSL, you have got to read that paper.
November 29, 2012
Beware the IPv6 DAD Race Condition
One extremely frustrating problem that arises with IPv6 under Linux is the race condition caused at system boot by IPv6's Duplicate Address Detection (DAD). DAD is a new feature in IPv6 that protects against IP address conflicts. The way it works is that after an address is added to an interface, the operating system uses the Neighbor Discovery Protocol to check if any other host on the network has the same address. If it finds a neighbor with the same address, the address is removed from the interface.
The problem is that until DAD can confirm that there is no
other host with the same address, the address is considered to be "tentative."
While it is in this state, attempts to bind() to the address
fail with EADDRNOTAVAIL, as if the address doesn't exist. That means
that if you have a service configured to listen on a particular IPv6 address,
and that IPv6 address is still tentative when the service starts, it will fail
to bind to that address. Very few programs will try to bind again later. Most
either continue without listening on the failed address, or fail to start
altogether. Apache, for example, fails to start if it can't bind to an address.
DAD is fast, but not always fast enough. Since services like Apache are started soon after networking is configured on system boot, there is a race condition. Sometimes your critical services start on boot, and sometimes they don't! This is clearly not acceptable behavior for a production server.
For this reason, I always disable DAD on servers that use IPv6. When DAD is disabled, addresses are immediately usable, just like they are with IPv4. Without DAD, I have to trust myself not to shoot myself in the foot with an address conflict, but that's nothing new. Besides, most of these servers are in data centers that restrict the IP addresses on the switch port anyways.
To disable DAD, you need to write 0 to /proc/sys/net/ipv6/conf/ethX/accept_dad,
where ethX is the interface, before you configure the interface. In Debian,
I accomplish this using a pre-up directive on the interface stanza, like this:
iface eth0 inet6 static
address 3ffe:ffff::4a:5000
netmask 64
gateway fe80::1
pre-up echo 0 > /proc/sys/net/ipv6/conf/eth0/accept_dad
Clearly, this is less than ideal. To begin with, this problem is not well-documented,
which will cause endless frustration to administrators trying to roll out IPv6. Even then, this
solution is sub-optimal and would lead to the demise of DAD on servers if widely implemented.
But a better solution would require more fundamental changes to either the operating system
or to the applications. The operating system could pause on boot until DAD completes. Ideally,
it would know which services listen on which addresses, and delay the start of only those
services. Services could retry failed binds after a delay, or set the Linux-specific
IP_FREEBIND socket option, which permits binding to a non-local or non-existent
address. (Unfortunately, IP_FREEBIND would also let you bind to an address that truly
doesn't exist.)
As IPv6 becomes more widespread, I expect this to be addressed in earnest, but until then, disabling DAD is the way to go.
Update (2013-05-05): A bug report has been filed in Debian about this issue. It proposes that ifupdown's init script not return until DAD completes on all interfaces.
November 28, 2012
Working Around the HE/Cogent IPv6 Peering Dispute
I was recently affected by the long-standing IPv6 peering dispute between Hurricane Electric and Cogent. On one of my systems which uses Hurricane Electric's IPv6 tunnel broker, connections to dual-homed hosts on Cogent's network were taking unreasonable amounts of time to establish, as attempts to use IPv6 had to time out before IPv4 was tried. Reverse DNS lookups on Cogent IP address space were taking 10 seconds to time out, causing frustrating delays for incoming ssh users, even over IPv4. Before you go blaming the tunnel, you should know that I observed the same problems from a server in a Hurricane Electric data center with native IPv6.
I've long been a fan of using reject routes to force faster failover when faced with less-than-ideal network conditions, so I turned to them again to work around this issue. I knew that if I added reject routes to Cogent's IPv6 address space, applications would immediately fail over to IPv4 without needing to first time out on IPv6.
First, I used Hurricane Electric's handy BGP Tookit to look up the IPv6 prefixes announced by AS174. AS174 is Cogent's autonomous system number. Conveniently, it was printed on Hurricane Electric's cake, saving me the trouble of looking it up.
{kind=link}
Then, I wrote a script to add reject routes to these prefixes:
#!/bin/sh
for prefix in 2001:0550::/32 2001:067c:12e8::/48 2001:0978::/32 2607:9700::/32 2607:f298:000a::/48 2607:f5d8::/32 2610:00f8:2f00::/48 2610:00f8:2fed::/48 2620:009a:8000::/48 2620:00fb::/48 2620:00fb::/56
do
ip -6 route add unreachable $prefix 2>/dev/null
done
exit 0
I stuck this in a system start up script so it's run every time the system boots.
This solves the problem, in the sense that there is no longer a long delay when accessing dual-homed Cogent hosts. Of course, it precludes the use of IPv6, which would be a problem if I needed to contact an IPv6-only Cogent host. Fortunately, hosts will be either dual-homed or IPv4-only for the foreseeable future. Still, I'm appalled that even after the World IPv6 Launch, two major transit providers are locked in such a lengthy IPv6 peering dispute.
November 18, 2012
Security Pitfalls of setgid Programs
If someone asked you whether it was safer to write a setuid program or a setgid program, what would you say? What about a setgid-only program versus a program that was both setuid and setgid? Instinctively, I would say setgid-only: setgid grants fewer privileges, which by principle of least privilege ought to be a good thing.
Not so. Here is a story that convinced me that setgid-only programs are inherently less safe than setuid programs.
The TAs at Brown's Computer Science department keep track of student grades using a homegrown system written in Python with some shell thrown in. One common command is report STUDENTLOGIN, which lists the grades for a particular student. The grades are stored in a file readable and writable only by the course's TA group, of which the TA staff are members.
Someone decided that it would be nice for students to be able to check their own grades at any time. So a setgid wrapper program called "mygrades" was written in C. It was owned by the course TA group and exec'd the report command with the username of the real user ID (i.e. the student who invoked the program) as the first argument. The wrapper program was written very carefully and scrutinized closely. In particular, the environment was completely wiped and replaced by a safe environment. What could possibly go wrong?
As it turns out, a lot. Here is a simplified version of the report command, which is a KornShell script that determines how it was called and execs the Python code appropriately:
#!/bin/ksh
# Assume that this script is installed one directory down from the course directory root (e.g. in tabin)
export COURSEDIR=$(readlink -f "$(dirname "$(whence "$0")")/..")
export EVALPIG_ROOT=$(readlink -f "$(dirname "$(readlink -f "$(whence "$0")")")")
export PYTHONPATH=$COURSEDIR/config:$EVALPIG_ROOT
exec python -O -c "__import__('$(basename "$0")').main()" "$@"
Can you spot the vulnerability? Keep in mind, the environment is completely safe. So are the arguments
(including $0).
The problem is that KornShell implements command substitution (i.e. $(...)) by creating a
temporary file (in /tmp), redirecting the output of the command to the temp file, and then reading it into
the variable. Since mygrades is a setgid wrapper, the user ID does not change. Consequentially, the
temporary files are owned by the user who invoked mygrades. The user can write to one of the temporary files
and as a result, inject arbitrary data into one of the script's variables. This is bad for any script, and really bad for
the script above. An attacker could effectively set an arbitrary PYTHONPATH and thus execute arbitrary Python code with the
permissions of the TA group.
Of course, the temporary file exists only for an instant (it's unlinked immediately after being opened), but I easily wrote a program that monitored /tmp with inotify and opened the file as soon as it was created. It didn't work every time, but if I ran mygrades in an infinite loop my attack would succeed within a minute.
What is counter-intuitive is that if the mygrades program had been setuid, this wouldn't have been a problem. The temp files would have been owned by the effective UID of mygrades and would have been tamperproof. Linux (and any decent Unix implementation) otherwise does a very good job protecting setgid programs from tampering by the process owner: the owner of a setgid process isn't allowed to ptrace it, debug it, etc. But the kernel can do nothing to protect the files that a setgid program creates on the filesystem. For this reason, unless you are sure that a program will not create temporary files at any point during its execution, or you are sure that a tampered-with temp file will not lead to a security compromise (which is probably a bad assumption), it is safer to make a program setuid than setgid-only.
November 9, 2012
How FUSE Can Break Rsync Backups
Update: See my followup article, Easily Running FUSE in an Isolated Mount Namespace, for a solution to this problem.
FUSE is cool, but by its nature has to introduce some non-standard semantics that you wouldn't see with a "real" filesystem. Sometimes these non-standard semantics can cause problems, as demonstrated by a recent experience I had with rsync-based backups on a multi-user Linux server that I administer.
The server performs regular snapshot backups of the filesystem using rsync and its --link-dest option to provide hard link-based dedupe. One day, an enterprising user mounted a sshfs filesystem in his home directory. That night, the snapshot backup failed with this error message:
rsync: readlink_stat("/home/aganlxl/cit") failed: Permission denied (13) rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1060) [sender=3.0.7]The problem is that, by default, only the user who owns the FUSE mount is allowed to access it. Not even root can. This is a security measure, since a malicious user could wreck havoc with a malicious FUSE mount (imagine an infinite filesystem, for example).
This behavior can be changed (with the 'allow_root' mount option, which has to be explicitly enabled by the super user in fuse.conf), but that's not the answer. Besides the security implications, that would cause rsync to descend into the sshfs mount and start backing up the remote system!
The problem is that rsync needs to be able to access everything it's backing up. Running as root, this is usually not a problem. Root not being able to access something on the filesystem seems weird, but is actually nothing new - root-squashed NFS mounts can also cause this. But FUSE mounts are worse. To begin with, unlike root-squashed NFS mounts, users are allowed to plop down FUSE mounts anywhere they like.
But worse, root isn't even allowed to stat FUSE mounts. This means that rsync's -x option (to not cross filesystem boundaries) can't even be used to exclude FUSE mounts, since rsync needs to stat the directory to determine if it's a mount point! This behavior is outside of POSIX, which says that stat shall return EACCES if "search permission is denied for a component of the path prefix."
In my opinion, a worthwhile addition to fuse.conf would be an option to restrict FUSE mounts to specific directories. With such an option, the admin could restrict FUSE mounts to locations that aren't backed up.
Until then, FUSE is disabled on this particular server.