October 17, 2014
Renewing an SSL Certificate Without Even Logging in to My Server
Yesterday I renewed the about-to-expire SSL certificate for one of my websites. I did so without running a single command, filling out a single form, taking out my credit card, or even logging into any server. All I did was open a link in an email and click a single button. Soon after, my website was serving a renewed certificate to visitors.
It's all thanks to the auto-renewal feature offered by my SSL certificate management startup, SSLMate, which I finally had a chance to dogfood yesterday with a real, live expiring certificate.
There are two halves to auto-renewals. The first, relatively straightforward half, is that the SSLMate service is constantly monitoring the expiration dates of my certificates. Shortly before a certificate expires, SSLMate requests a new certificate from a certificate authority. As with any SSL certificate purchase, the certificate authority emails me a link which I have to click to confirm that I still control the domain. Once I've done that, the certificate authority delivers the new certificate to SSLMate, and SSLMate stores it in my SSLMate account. SSLMate charges the credit card already on file in my account, just like any subscription service.
But a certificate isn't very useful sitting in my SSLMate account. It needs to be installed on my web servers so that visitors are served with the new certificate. This is the second half of auto-renewals. If I were using a typical SSL certificate vendor, this step would probably involve downloading an email attachment, unzipping it, correctly assembling the certificate bundle, installing it on each of my servers, and restarting my services. This is tedious, and worse, it's error-prone. And as someone who believes strongly in devops, it offends my sensibilities.
Fortunately, SSLMate isn't a typical SSL certificate vendor. SSLMate comes with a command line
tool to help manage your SSL certificates. Each of my servers runs the following script
daily (technically, it runs from a configuration management system,
but it could just as easily run from a cron job in /etc/cron.daily):
#!/bin/sh if sslmate download --all then service apache2 restart service titus restart fi exit 0
The sslmate download command downloads certificates from my SSLMate
account to the /etc/sslmate directory on the server. --all tells sslmate
to look at the private keys in /etc/sslmate and download the corresponding
certificate for each one (alternatively, I could explicitly specify certificate
common names on the command line). sslmate download exits with a zero status code
if new certificates were downloaded, or a non-zero status if the certificates
were already up-to-date. The if condition tests for a zero exit code, and
restarts my SSL-using services if new certificates were downloaded.
On most days of the year, this script does nothing, since my certificates are already up-to-date. But on days when a certificate has been renewed, it comes to life, downloading new certificate files (not just the certificate, but also the chain certificate) and restarting services so that they use the new files. This is devops at its finest, applied to SSL certificate renewals for the first time.
You may be wondering - is it a good idea to do this unattended? I think so. First, the risk of installing a broken certificate is very low, and certainly lower than when an installation is done by hand. Since SSLMate takes care of assembling the certificate bundle for you, there's no risk of forgetting to include the chain certificate or including the wrong one. Chain certificate problems are notoriously difficult to debug, since they don't materialize in all browsers. While tools such as SSL Labs are invaluable for verifying certificate installation, they can only tell you about a problem after you've installed a bad certificate, which is too late to avoid downtime. Instead, it's better to automate certificate installation to eliminate the possibility of human error.
I'm also unconcerned about restarting Apache unattended. sslmate download contains a failsafe that refuses to install a new certificate if it doesn't match the private key, ensuring that it won't install a certificate that would prevent Apache from starting. And I haven't done anything reckless with my Apache configuration that might make restarts unreliable. Besides, it's already essential to be comfortable with restarting system services, since you may be required to restart a service at any time in response to a security update.
One more thing: this certificate wasn't originally purchased through SSLMate, yet SSLMate was able to renew it, thanks to SSLMate's upcoming import feature. A new command, sslmate import, will let you import your existing certificates to your SSLMate account. Once imported, you can set up your auto-renewal cron job, and you'll be all set when your certificates begin to expire. And you'll be charged only when a certificate renews; importing certificates will be free.
sslmate import is in beta testing and will be released soon. If you're interested in taking part in the beta, shoot an email to sslmate@sslmate.com. Also consider subscribing to the SSLMate blog or following @SSLMate on Twitter so you get future announcements - we have a lot of exciting development in the pipeline.
September 30, 2014
CloudFlare: SSL Added and Removed Here :-)
One of the more infamous leaked NSA documents was a slide showing a hand-drawn diagram of Google's network architecture, with the comment "SSL added and removed here!" along with a smiley face, written underneath the box for Google's front-end servers.
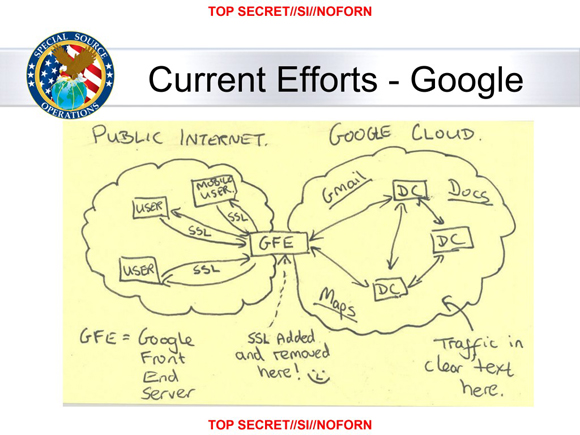 "SSL added and removed here! :-)"
"SSL added and removed here! :-)"
"SSL added and removed here! :-)"
The point of the diagram was that although Google tried to protect their users' privacy by using HTTPS to encrypt traffic between web browsers and their front-end servers, they let traffic travel unencrypted between their datacenters, so their use of HTTPS was ultimately no hindrance to the NSA's mass surveillance of the Internet.
Today the NSA can draw a new diagram, and this time, SSL will be added and removed not by a Google front-end server, but by a CloudFlare edge server. That's because, although CloudFlare has taken the incredibly generous and laudable step of providing free HTTPS by default to all of their customers, they are not requiring the connection between CloudFlare and the origin server to be encrypted (they call this "Flexible SSL"). So although many sites will now support HTTPS thanks to CloudFlare, by default traffic to these sites will be encrypted only between the user and the CloudFlare edge server, leaving plenty of opportunity for the connection to be eavesdropped beyond the edge server.
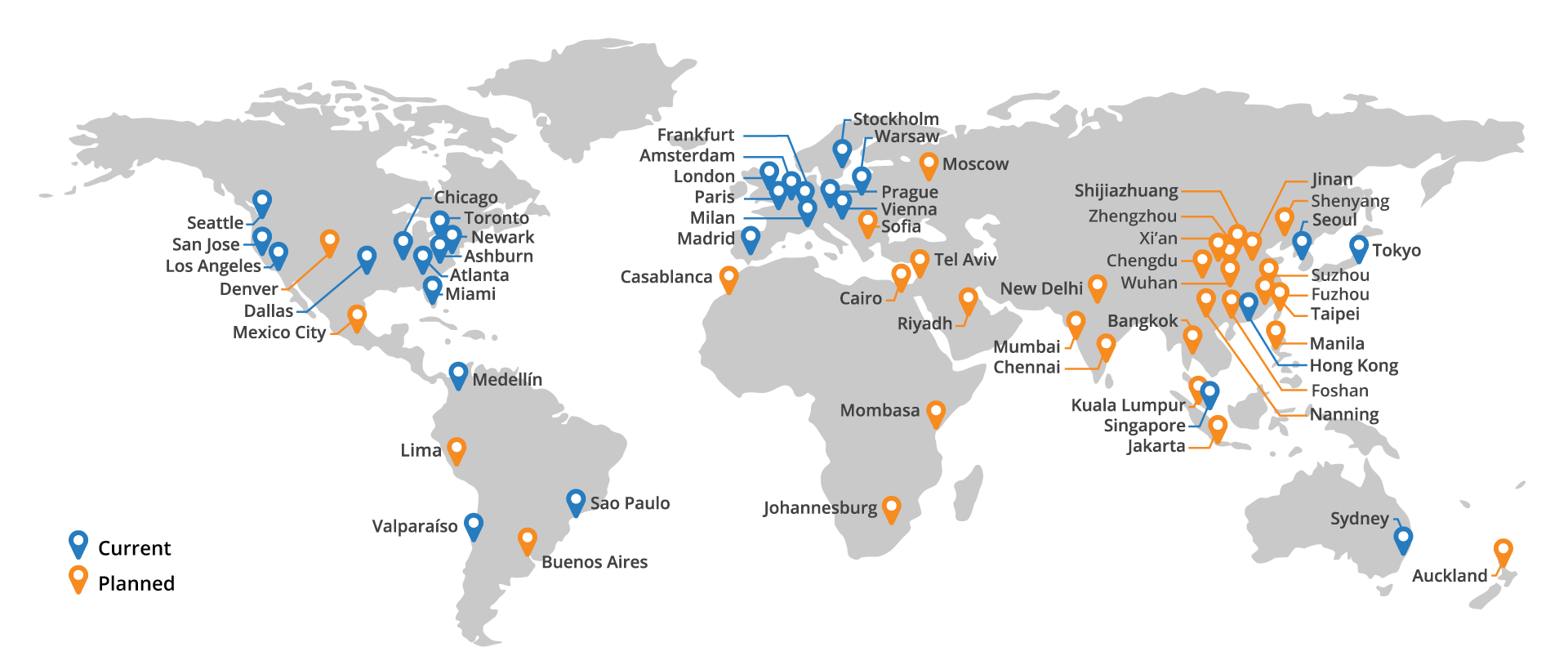
Arguably, encrypting even part of the connection path is better than the status quo, which provides no encryption at all. I disagree, because CloudFlare's Flexible SSL will lull website visitors into a false sense of security, since these partially-encrypted connections will appear to the browser as normal HTTPS connections, padlock and all. There will be no distinction made whatsoever between a connection that's protected all the way to the origin, and a connection that's protected only part of the way. Providing a false sense of security is often worse than providing no security at all, and I find the security of Flexible SSL to be quite lacking. That's because CloudFlare aims to put edge nodes as close to the visitor as possible, which minimizes latency, but also minimizes the percentage of an HTTPS connection which is encrypted. So although Flexible SSL will protect visitors against malicious local ISPs and attackers snooping on coffee shop WIFI, it provides little protection against nation-state adversaries. This point is underscored by a map of CloudFlare's current and planned edge locations, which shows a presence in 37 different countries, including China. China has abysmal human rights and pervasive Internet surveillance, which is troubling because CloudFlare explicitly mentions human rights organizations as a motivation for deploying HTTPS everywhere:
{kind=link}
Every byte, however seemingly mundane, that flows encrypted across the Internet makes it more difficult for those who wish to intercept, throttle, or censor the web. In other words, ensuring your personal blog is available over HTTPS makes it more likely that a human rights organization or social media service or independent journalist will be accessible around the world.
It's impossible for Flexible SSL to protect a website of a human rights organization from interception, throttling, or censoring when the connection to that website travels unencrypted through the Great Firewall of China. What's worse is that CloudFlare includes the visitor's original IP address in the request headers to the origin server, which of course is unencrypted when using Flexible SSL. A nation-state adversary eavesdropping on Internet traffic will therefore see not only the URL and content of a page, but also the IP address of the visitor who requested it. This is exactly the same situation as unencrypted HTTP, yet as far as the visitor can tell, the connection is using HTTPS, with a padlock icon and an https:// URL.
It is true that HTTPS has never guaranteed the security of a connection behind the host that terminates the SSL, and it's already quite common to terminate SSL in a front-end host and forward unencrypted traffic to a back-end server. However, in almost all instances of this architecture, the SSL terminator and the back-end are in the same datacenter on the same network, not in different countries on opposite sides of the world, with unencrypted connections traveling over the public Internet. Furthermore, an architecture where unencrypted traffic travels a significant distance behind an SSL terminator should be considered something to fix, not something to excuse or encourage. For example, after the Google NSA slide was released, Google accelerated their plans to encrypt all inter-datacenter traffic. In doing so, they strengthened the value of HTTPS. CloudFlare, on the other hand, is diluting the value of HTTPS, and in astonishing numbers: according to their blog post, they are doubling the number of HTTPS sites on the Internet from 2 million to 4 million. That means that after today, one in two HTTPS websites will be using encryption where most of the connection path is actually unencrypted.
Fortunately, CloudFlare has an alternative to Flexible SSL which is free and provides encryption between CloudFlare and the origin, which they "strongly recommend" site owners enable. Unfortunately, it requires manual action on the part of website operators, and getting users to follow security recommendations, even when strongly recommended, is like herding cats. The vast majority of those 2 million website operators won't do anything, especially when their sites already appear to be using HTTPS and thus benefit from the main non-security motivation for HTTPS, which is preference in Google search rankings.
This is a difficult problem. CloudFlare should be commended for tackling it and for their generosity in making their solution free. However, they've only solved part of the problem, and this is an instance where half measures are worse than no measures at all. CloudFlare should abolish Flexible SSL and make setting up non-Flexible SSL easier. In particular, they should hurry up the rollout of the "CloudFlare Origin CA," and instead of requiring users to submit a CSR to be signed by CloudFlare, they should let users download, in a single click, both a private key and a certificate to be installed on their origin servers. (Normally I'm averse to certificate authorities generating private keys for their users, but in this case, it would be a private CA used for nothing but the connection between CloudFlare and the origin, so it would be perfectly secure for CloudFlare to generate the private key.)
If CloudFlare continues to offer Flexible SSL, they should at least include an HTTP header in the response indicating that the connection was not encrypted all the way to the origin. Ideally, this would be standardized and web browsers would not display the same visual indication as proper HTTPS connections if this header is present. Even without browser standardization, the header could be interpreted by a browser extension that could be included in privacy-conscious browser packages such as the Tor Browser Bundle. This would provide the benefits of Flexible SSL without creating a false sense of security, and help fulfill CloudFlare's stated goal to build a better Internet.
September 6, 2014
SHA-1 Certificate Deprecation: No Easy Answers
Google recently announced that they will be phasing out support for SHA-1 SSL certificates in Chrome, commencing almost immediately. Although Microsoft was the first to announce the deprecation of SHA-1 certificates, Google's approach is much more aggressive than Microsoft's, and will start treating SHA-1 certificates differently well before the January 1, 2017 deadline imposed by Microsoft. A five year SHA-1 certificate purchased after January 1, 2012 will be treated by Chrome as "affirmatively insecure" starting in the first half of 2015.
This has raised the hackles of Matthew Prince, CEO of CloudFlare. In a comment on Hacker News, Matthew cites the "startling" number of browsers that don't support SHA-2 certificates (namely, pre-SP3 Windows XP and pre-2.3 Android) and expresses his concern that the aggressive deprecation of SHA-1 will lead to organizations declining to support HTTPS. This comment resulted in a very interesting exchange between him and Adam Langley, TLS expert and security engineer at Google, who, as you'd expect, supports Google's aggressive deprecation plan.
Matthew raises legitimate concerns. We're at a unique point in history: there is incredible momentum behind converting sites to HTTPS, even sites that traditionally would not have used HTTPS, such as entirely static sites. The SHA-1 deprecation might throw a wrench into this and cause site operators to reconsider switching to HTTPS. Normally I have no qualms with breaking some compatibility eggs to make a better security omelette, but I'm deeply ambivalent about the timeframe of this deprecation. Losing the HTTPS momentum would be incredibly sad, especially since switching to HTTPS provides an immediate defense against large-scale passive eavesdropping.
Of course, Adam raises a very good point when he asks "if Microsoft's 2016/2017 deadline is reckless, what SHA-1 deprecation date would be right by your measure?" In truth, the Internet should have already moved away from SHA-1 certificates. Delaying the deprecation further hardly seems like a good idea.
Ultimately, there may be no good answer to this question, and it's really just bad luck and bad timing that this needs to happen right when HTTPS is picking up momentum.
This affects me as more than just a site operator, since I resell SSL certificates over at SSLMate. Sadly, SSLMate's upstream certificate authority, RapidSSL, does not currently support SHA-2 certificates, and has not provided a definite timeframe for adding support. RapidSSL is not alone: Gandi does not support SHA-2 either, and GoDaddy's SHA-2 support is purportedly a little bumpy. The fact that certificate authorities are not all ready for this change makes Google's aggressive deprecation schedule all the more stressful. On the other hand, I expect RapidSSL to add SHA-2 support soon in response to Google's announcement. If I'm correct, it will certainly show the upside of an aggressive deprecation in getting lethargic players to act.
In the meantime, SSLMate will continue to sell SHA-1 certificates, though it will probably stop selling certificates that are valid for more than one or two years. Switching to a certificate authority that already supports SHA-2 is out of the question, since they are either significantly more expensive or take a long time to issue certificates, which doesn't work with SSLMate's model of real time purchases from the command line. When RapidSSL finally adds SHA-2 support, SSLMate customers will be able to replace their existing SHA-1 certificates for free, and SSLMate will do its best to make this process as easy as possible.
Speaking of certificate lifetimes, Adam Langley made the case in the Hacker News thread that site operators should purchase certificates that last only a year. I agree heartily. In addition to Adam's point that short-lived certificates insulate site operators from changes like the SHA-1 deprecation, I'd like to add that they're more secure because certificate revocation doesn't really work. If your private key is compromised, you're not truly safe until your certificate expires, so the shorter the lifetime the better. The main argument against short-lived certificates has always been that they're really inconvenient, so I'm happy to say that at SSLMate I'm working on some very exciting features that will make yearly certificate renewals extremely easy. Stay tuned for an announcement next week.
August 12, 2014
STARTTLS Considered Harmful
There are two ways that otherwise plain text protocols can provide encryption with TLS. The first way is to listen on two ports: one port that is always plain text, and a second port that is always encrypted with TLS. The other way is to use a single port on which communication starts out unencrypted, but can be "upgraded" to a TLS encrypted connection using an application-level command specific to the protocol. HTTP/HTTPS uses exclusively the first approach, with ports 80 and 443. The second approach, called STARTTLS, is used by SMTP, XMPP, IMAP, and POP3, though several of those protocols also support the first approach.
There's a clear bias for STARTTLS in the IETF's email standards. The use of alternative TLS-only ports for IMAP, POP3, and SMTP was never formally standardized: people just started doing it that way, and although port numbers were registered for the purpose, the registration of the encrypted SMTP (SMTPS) port (465) was later rescinded. When the IETF finally standardized the use of TLS with IMAP and POP3 in 1999, they prescribed the use of STARTTLS and gave several reasons why STARTTLS should be used instead of an alternative TLS-only port. Briefly, the reasons are:
- Separate ports lead to a separate URL scheme, which means the user has to choose between them. The software is often more capable of making this choice than the user.
- Separate ports imply a model of either "secure" or "not secure," which can be misleading. For example, the "secure" port might be insecure because it's using export-crippled ciphers, or the normal port might be using a SASL mechanism which includes a security layer.
- Separate ports has caused clients to implement only two security policies: use TLS or don't use TLS. The desirable security policy "use TLS when available" would be cumbersome with the separate port model, but is simple with STARTTLS.
- Port numbers are a limited resource.
Except for reason four, these reasons are pretty terrible. Reason one is not very true: unless the software keeps a database of hosts which should use TLS, the software is incapable of making the choice between TLS and non-TLS on behalf of the user without being susceptible to active attacks. (Interestingly, web browsers have recently started keeping a database of HTTPS-only websites with HSTS preload lists, but this doesn't scale.)
Reason three is similarly dubious because "use TLS when available" is also susceptible to active attacks. (If the software detects that TLS is not available, it doesn't know if that's because the server doesn't support it or if it's because an active attacker is blocking it.)
Reason two may have made some sense in 1999, but it certainly doesn't today. The export cipher concern was mooted when export controls were lifted in 2000, leading to the demise of export-crippled ciphers. I have no idea how viable SASL security layers were in 1999, but in the last ten years TLS has clearly won.
So STARTTLS is really no better than using an alternative TLS-only port. But that's not all. There are several reasons why STARTTLS is actually worse for security.
The first reason is that STARTTLS makes it impossible to terminate TLS in a protocol-agnostic way. It's trivial to terminate a separate-port protocol like HTTPS in a software proxy like titus or in a hardware load balancer: you simply accept a TLS connection and proxy the plain text stream to the backend's non-TLS port. Terminating a STARTTLS protocol, on the other hand, requires the TLS terminator to understand the protocol being proxied, so it can watch for the STARTTLS command and only upgrade to TLS once the command is sent. Supporting IMAP/POP3/SMTP isn't too difficult since they are simple line-based text protocols. (Though you have to be careful - you don't want the TLS terminator to misfire if it sees the string "STARTTLS" inside the body of an email!) XMPP, on the other hand, is an XML-based protocol, and do you really want your TLS terminator to contain an XML parser?
I care about this because I'd like to terminate TLS for my SMTP, IMAP, and XMPP servers in the highly-sandboxed environment provided by titus, so that a vulnerability in the TLS implementation can't compromise the state of my SMTP, IMAP, and XMPP servers. STARTTLS makes it needlessly difficult to do this.
Another way that STARTTLS harms security is by adding complexity. Complexity is a fertile source of security vulnerabilities. Consider CVE-2011-0411, a vulnerability caused by SMTP implementations failing to discard SMTP commands pipelined with the STARTTLS command. This vulnerability allowed attackers to inject SMTP commands that would be executed by the server during the phase of the connection that was supposed to be protected with TLS. Such a vulnerability is impossible when the connection uses TLS from the beginning.
STARTTLS also adds another potential avenue for a protocol downgrade attack. An active attacker can strip out the server's advertisement of STARTTLS support, and a poorly-programmed client would fall back to using the protocol without TLS. Although it's trivial for a properly-programmed client to protect against this downgrade attack, there are already enough ways for programmers to mess up TLS client code and it's a bad idea to add yet another way. It's better to avoid this pitfall entirely by connecting to a port that talks only TLS.
Fortunately, despite the IETF's recommendation to use STARTTLS and the rescinding of the SMTPS port assignment, IMAP, POP3, and SMTP on dedicated TLS ports are still widely supported by both server and client email implementations, so you can easily avoid STARTTLS with these protocols. Unfortunately, the SMTPS port is only used for the submission of authenticated mail by mail clients. Opportunistic encryption between SMTP servers, which is extremely important for preventing passive eavesdropping of email, requires STARTTLS on port 25. And modern XMPP implementations support only STARTTLS.
Moving forward, this shouldn't even be a question for new protocols. To mitigate pervasive monitoring, new protocols should have only secure versions. They can be all TLS all the time. No need to choose between using STARTTLS and burning an extra port number. I just wish something could be done about the existing STARTTLS-only protocols.
July 13, 2014
LibreSSL's PRNG is Unsafe on Linux [Update: LibreSSL fork fix]
The first version of LibreSSL portable, 2.0.0, was released a few days ago (followed soon after by 2.0.1). Despite the 2.0.x version numbers, these are only preview releases and shouldn't be used in production yet, but have been released to solicit testing and feedback. After testing and examining the codebase, my feedback is that the LibreSSL PRNG is not robust on Linux and is less safe than the OpenSSL PRNG that it replaced.
Consider a test program, fork_rand. When linked with OpenSSL, two different
calls to RAND_bytes return different data, as expected:
When the same program is linked with LibreSSL, two different calls to RAND_bytes return the same data, which is a
catastrophic failure of the PRNG:
The problem is that LibreSSL provides no way to safely use the PRNG after a fork. Forking
and PRNGs are a thorny issue - since fork() creates a nearly-identical clone of the parent process,
a PRNG will generate identical output in the parent and child processes unless it is reseeded.
LibreSSL attempts to detect when a fork occurs by checking the PID (see line 122). If it differs from the last
PID seen by the PRNG, it knows that a fork has occurred and automatically reseeds.
This works most of the time. Unfortunately, PIDs are typically only 16 bits long and thus wrap around fairly often. And while a process can never have the same PID as its parent, a process can have the same PID as its grandparent. So a program that forks from a fork risks generating the same random data as the grandparent process. This is what happens in the fork_rand program, which repeatedly forks from a fork until it gets the same PID as the grandparent.
OpenSSL faces the same issue. It too attempts to be fork-safe,
by mixing the PID into the PRNG's output,
which works as long as PIDs don't wrap around. The difference is
that OpenSSL provides a way to explicitly reseed the PRNG by calling RAND_poll.
LibreSSL, unfortunately, has turned RAND_poll into a no-op (lines 77-81). fork_rand calls RAND_poll after forking,
as do all my OpenSSL-using programs in production, which is why fork_rand is safe under OpenSSL but not LibreSSL.
You may think that fork_rand is a contrived example or that it's unlikely in practice for a process to end up with the same PID as its grandparent. You may be right, but for security-critical code this is not a strong enough guarantee. Attackers often find extremely creative ways to manufacture scenarios favorable for attacks, even when those scenarios are unlikely to occur under normal circumstances.
Bad chroot interaction
A separate but related problem is that LibreSSL provides no good way to use the PRNG from a process running inside a chroot jail.
Under Linux, the PRNG is seeded by reading from /dev/urandom upon the first use of RAND_bytes. Unfortunately,
/dev/urandom usually doesn't exist inside chroot jails. If LibreSSL fails to read entropy from /dev/urandom,
it first tries to get random data using the deprecated sysctl syscall, and if that fails (which will start happening
once sysctl is finally removed), it falls back to a truly scary-looking function (lines 306-517) that attempts to get entropy from sketchy
sources such as the PID, time of day, memory addresses, and other properties of the running process.
OpenSSL is safer for two reasons:
- If OpenSSL can't open
/dev/urandom,RAND_bytesreturns an error code. Of course the programmer has to check the return value, which many probably don't, but at least OpenSSL allows a competent programmer to use it securely, unlike LibreSSL which will silently return sketchy entropy to even the most meticulous programmer. - OpenSSL allows you to explicitly seed the PRNG by calling
RAND_poll, which you can do before entering the chroot jail, avoiding the need to open/dev/urandomonce in the jail. Indeed, this is how titus ensures it can use the PRNG from inside its highly-isolated chroot jail. Unfortunately, as discussed above, LibreSSL has turnedRAND_pollinto a no-op.
What should LibreSSL do?
First, LibreSSL should raise an error if it can't get a good source of entropy. It can do better than OpenSSL by killing the process instead of returning an easily-ignored error code. In fact, there is already a disabled code path in LibreSSL (lines 154-156) that does this. It should be enabled.
Second, LibreSSL should make RAND_poll reseed the PRNG as it does under OpenSSL. This will allow the programmer to guarantee
safe and reliable operation after a fork and inside a chroot jail. This is especially important as LibreSSL aims to be a
drop-in replacement for OpenSSL. Many properly-written programs have come to rely on OpenSSL's RAND_poll behavior for safe
operation, and these programs will become less safe when linked with LibreSSL.
Unfortunately, when I suggested the second change on Hacker News, a LibreSSL developer replied:
The presence or need for a [RAND_poll] function should be considered a serious design flaw.
I agree that in a perfect world, RAND_poll would not be necessary, and that its need is evidence of a design flaw. However, it is evidence of a design flaw not in the cryptographic library, but in the operating system. Unfortunately, Linux provides no reliable way to detect that a process has forked, and exposes entropy via a device file instead of a system call. LibreSSL has to work with what it's given, and on Linux that means RAND_poll is an unfortunate necessity.
Workaround
If the LibreSSL developers don't fix RAND_poll, and you want your code to work safely with
both LibreSSL and OpenSSL, then I recommend putting the following code after you fork or before you chroot (i.e. anywhere you would currently need RAND_poll):
unsigned char c; if (RAND_poll() != 1) { /* handle error */ } if (RAND_bytes(&c, 1) != 1) { /* handle error */ }
In essence, always follow a call to RAND_poll with a request for
one random byte. The RAND_bytes call will force LibreSSL to seed the
PRNG if it's not already seeded, making it unnecessary to later open
. It will also force LibreSSL
to update the last seen PID, fixing the grandchild PID issue. (Edit: the LibreSSL
PRNG periodically re-opens and re-reads /dev/urandom from inside the chroot jail/dev/urandom to mix in additional entropy,
so unfortunately this won't avoid the need to open /dev/urandom from inside the
chroot jail. However, as long as you have a good initial source of entropy, mixing in the sketchy
entropy later isn't terrible.)
I really hope it doesn't come to this. Programming with
OpenSSL already requires dodging numerous traps and pitfalls, often by deploying
obscure workarounds. The LibreSSL developers, through their well-intended effort
to eliminate the pitfall of forgetting to call RAND_poll,
have actually created a whole new pitfall with its own obscure workaround.
Update (2014-07-16 03:33 UTC): LibreSSL releases fix for fork issue
LibreSSL has released a fix for the fork issue! (Still no word on the chroot/sketchy entropy issue.) Their fix is to use pthread_atfork to register a callback that reseeds the PRNG when fork() is called. Thankfully, they've made this work without requiring the program to link with -lpthread.
I have mixed feelings about this solution, which was discussed in a sub-thread on Hacker News. The fix is a huge step in the right direction but is not perfect - a program that invokes the clone syscall directly will bypass the atfork handlers (Hacker News commenter colmmacc suggests some legitimate reasons a program might do this). I still wish that LibreSSL would, in addition to implementing this solution, just expose an explicit way for the programmer to reseed the PRNG when unusual circumstances require it. This is particularly important since OpenSSL provides this facility and LibreSSL is meant to be a drop-in OpenSSL replacement.
Finally, though I was critical in this blog post, I really appreciate the work the LibreSSL devs are doing, especially their willingness to solicit feedback from the community and act on it. (I also appreciate their willingness to make LibreSSL work on Linux, which, despite being a Linux user, I will readily admit is lacking in several ways that make a CSPRNG implementation difficult.) Ultimately their work will lead to better security for everyone.